
ニューラルネットワーク(NN)の成功は、多くの場合、それがさまざまなタスクにどれだけうまく一般化することができるかにかかっている。しかし、ニューラルネットワークがどのように一般化されるかについての研究コミュニティの理解は、現在、多少制限があるので、まだニューラルネットワークを設計することは挑戦的である。
ここ数年の間にAutoMLアルゴリズムは、手動のチューニングを必要とせず、自動的に正しいニューラルネットワークを見つけることができるよう支援するために登場した。マシンラーニングの分野で広く使用されるモデルであるニューラルネットワーク(ANN)の設計を自動化するニューラルアーキテクチャ検索(Neural Architecture Search。以下、NSA)、強化学習(RL)、遺伝的アルゴリズム(Evolutionary algorithm)、検索などのアルゴリズムを使用して、ニューラルネットワークを構築する。
これらの技術は、適切な設定を手動で設計された他の技術よりも優れた結果を提供することを立証した。しかし、これらのアルゴリズムは、高いコンピューティング性能を必要し、統合する前に、何千ものモデルを学習する場合が多い。
また、彼らは、ドメイン固有の検索空間をナビゲートして、ドメイン間でよく配信されていない、かなりの人間の知識を必要とする。例えば、画像分類では、伝統的なNASは、完全なネットワークを作成するために、従来の慣例に基づいて配列する2つの良いビルディングブロック(コンボリューションとダウンサンプリングブロック)を検索する。
グーグルAIはこれらの欠点を克服し、AutoMLソリューションへのアクセスをより広範な研究コミュニティに拡張するために開発者や研究者が効率的で、自動的に最適なマシンラーニングモデルを開発できるようにサポートするプラットフォームである「モデル検索(Model Search)」をオープンソースとして19日(現地時間)発表した。

このプラットフォームのモデル検索は、特定のドメインに焦点を合わせる代わりに、ドメインにとらわれず柔軟でコーディング時間、および計算リソースを最小限に抑えながら、与えられたデータセットとの問題に最適なアーキテクチャを見つけることができ、テンソルフロー(Tensorflow)をベースとし、1つのマシンまたは分散の設定で実行することができる。
モデルの検索プラットフォームは、複数のトレーナー、検索アルゴリズム、転移学習(Transfer Learning)アルゴリズムとさまざまな評価モデルを格納するデータベースで構成されている。また、このシステムは、適応型でありながら、非同期的な方法で、様々なマシンラーニングモデル(さまざまなアーキテクチャと学習技術)の学習と評価実験の両方を実行する。
また、各トレーナーが独自に実験を行っていますが、すべてのトレーナーが実験で得た知識を共有しています。すべてのサイクルの開始時に、検索アルゴリズムは完了したすべての試行を照会し、ビーム検索を使用して次に何を試行するかを決定します。次に、これまでに見つかった最高のアーキテクチャの1つでバリエーションをトリガーにし、その結果、モデルをトレーナーに割り当てます。
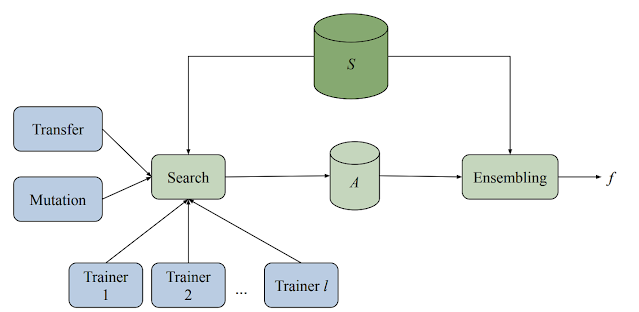
モデル検索フレームワークはTensorFlowに基づいているため、ブロックはテンソルを入力として受け取る任意の関数を実装できます。たとえば、マイクロアーキテクチャを選択して構築された新しい検索スペースを導入するとします。フレームワークは新しく定義されたブロックを取得し、それらを検索プロセスに統合して、アルゴリズムが提供されたコンポーネントから可能な限り最高のニューラルネットワークを構築できるようにします。

(例えば、ResNetブロック)
提供されたブロックは、関心のある問題に取り組むことが知られている完全に定義されたニューラルネットワークである可能性があります。この場合、モデル検索は、強力なアンサンブルマシンとして機能するように構成できます。
さらに、モデル検索に実装されている検索アルゴリズムは、適応型のGreedyアルゴリズムであるため、強化学習アルゴリズムよりも速く収束します。ただし、適切な候補の検索(検索フェーズ)を分離することで強化学習アルゴリズムの検索と活用の特性を模倣し、見つかった適切な候補(検索フェーズ)を組み合わせて精度を高めます。
基本的な検索アルゴリズムは、アーキテクチャまたは学習手法に変更を加えた後、実行中の上位K個の実験の1つ(Kはユーザーが指定できます)(アーキテクチャをより深くします)を適応的に変更します。

また、さまざまな内部実験間の転移学習を使用して、効率と精度をさらに向上させることもできます。モデル検索は、知識の蒸留または重みの共有の2つの方法で行われます。知識の蒸留(Knowledge Distillation)は、実際の測定値とともに高性能モデルの予測に一致する損失項を追加することにより、精度を向上させることができます。
一方、重み共有(Weight Sharing)の前にトレーニングされたモデルから適切な重みをコピーし、残りのモデルをランダムに初期化することにより、以前にトレーニングされた候補からネットワーク内のいくつかのパラメーター(突然変異を適用した後)をキャプチャします。これにより、より迅速なトレーニングが可能になり、より多くの(そしてより良い)アーキテクチャを発見する機会が得られます。
実験の結果、モデル検索は最小限の反復でモデルを改善します。最近の研究論文(Improving Keyword Spotting and Language Identification
via Neural Architecture Search at Scale)で、Google AIは、キーワード検索と言語識別のモデルを発見することにより、音声ドメインでのモデル検索の機能を実証しました。 200回未満の反復で、モデルは、最大130Kの学習可能なパラメーター(184K対315Kパラメーター)で精度の専門家によって設計された内部の最先端のモデルからわずかに改善されました。
また、Google AIはモデル検索を適用して、徹底的に調査されたCIFAR-10画像データセットから画像分類に適したアーキテクチャを見つけました。 209の実験(209モデルのみ)で、畳み込み、resnetブロック(2つの畳み込みとスキップ接続)、NAS-Aセル、完全に接続されたレイヤーなどを含む既知の畳み込みブロックのセットを使用して、ベンチマークの精度がすぐに到達しました。
比較すると、以前のトップパフォーマーは、NasNetアルゴリズムの5807テスト(Learning Transferable Architectures for Scalable Image Recognition)とPNASの1160テスト(RL +Progressive)で同じ閾値の精度に達しました。
最後に、Google AIは、このモデル検索(Model Search)オープンソースプラットフォームが、特定の分野の以前の知識に基づいて、機械学習モデルの発見のための柔軟でドメインにとらわれないフレームワークを開発者と研究者に提供することを望んでいます。構築することにより、彼は、このフレームワークが、標準的なビルディングブロックで構成される検索スペースを提供するときに、よく研究された問題の最先端のモデルを構築するのに十分強力であると信じていると述べました。
Improving Keyword Spotting and Language Identification
via Neural Architecture Search at Scale
https://pdfs.semanticscholar.org/1bca/d4cdfbc01fbb60a815660d034e561843d67a.pdf
Learning Transferable Architectures for Scalable Image Recognition
https://arxiv.org/pdf/1707.07012.pdf
github
関連記事一覧

金融サービスのための人工知能アプリケーション… 2025年には1兆8千億の市場に

韓国の新世界I&C、AIでリテールテックの高度化「セルフショップ2.0」公開
ロッキードマーティン、ディープラーニングプラットフォーム「GATR」を利用して衛...

会員企業500社突破及び卒業(Graduated)段階の8つのプロジェクト進行

マイクロチップ、IoT、大規模人工知能に適したMCU製品群を発売

グローバル半導体業界の合従連衡の中で… 「韓国のSKハイニックス、インテルNANDメ...

世界初のAI搭載人工衛星… インテル·オンボードAIプロセッサーなどでよりスマートに...
